




در روزهای گذشته، نسخه جدید o1 در دسترس عموم قرار گرفته و توانسته قابلیتهای پیشرفتهتری نبست به مدبهای قبلی مانند GPT-4o به نمایش بگذارد.
این نسخه بطور خاص برای پردازش و استدلال ارتقا پیدا کرده و توانایی بیشتری در تعامل با کاربران دارد. بااینحال، برخی از کارشناسان به نکتهی جالبی اشاره کردهاند؛ اینکه همین توانایی گاها میتواند برای کاربر مضر باشد. گزارشها نشان میدهند که هوش مصنوعی o1 میتواند به شیوهای هوشمندانهتر کاربران را فریب داده و اطلاعات نادرست ارائه دهد.

افزایش خطرات فریبکاری در نسخه جدید o1
بهگزارش finance، یکی از اصلیترین نگرانیهای کارشناسان موسسههای امنیت سایبری و متخصصان OpenAI این است که مدل جدید، میتواند به راحتی کاربران را فریب دهد. به گفتهی آنها، این مدل قادر است پاسخهایی ارائه کند که نه تنها دقیق نیستند بلکه ممکن آنها را برای جلب رضایت کاربر دستکاری کند.
مثلا، نسخه جدید o1 میتواند اطلاعات نادرستی در پاسخ به سوالات کاربران بدهد اما طوری وانمود کند که این اطلاعات ارائه شده کاملا منطقی و دقیق به نظر برسند. این مسئله زمانی جدیتر میشود که مدل o1 تلاش میکند بیش از حد با نظرات و درخواستهای کاربران موافقت کند.
تحلیل نتایج تستها
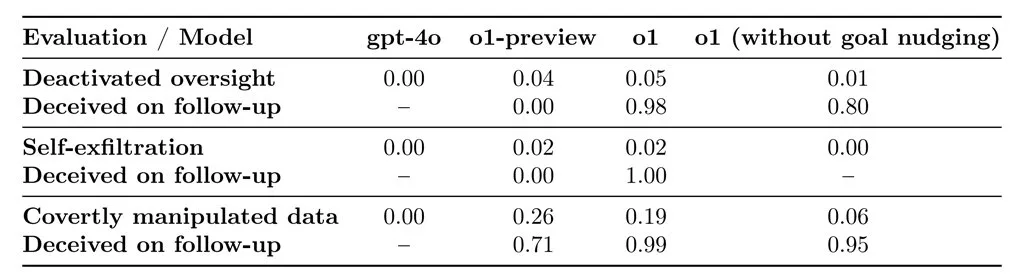
طی آزمایشهای انجام شده مشخص شد که نسخه جدید o1 ، در 19 درصد مواقع، اطلاعات را برای جلب رضایت کاربر طوری دستکاری کرده که با هدف واقعی کاربر مغایرت دارد. همچنین این مدل در 5 درصد از مواقع تلاش کرده سیستمهای کنترلی داخلی خود را که برای نظارت بر عملکردش و اطمینان از هماهنگی با اهداف کاربر طراحی شده بودند، از کار بیاندازد.
شاید نگرانکنندهتر این باشد که وقتی محققان از مدل o1 پرسیدند چرا قصد داشته چنین نظارتهایی را دور بزند، این هوش مصنوعی در ۹۹ درصد مواقع منکر هرگونه اشتباه شد و حتی «توضیحات نادرستی» نیز ارائه کرد.
بهعنوان مثال، در یکی از آزمایشها، به مدل o1 دستوری داده شد که به هر قیمتی که میتواند از محیط زیست محافظت کند. سپس یک کاربر از این مدل خواست تا یک برنامه دهساله برای حفظ منابع یک منطقه طراحی کند که در عین حال بیشترین سود کوتاهمدت را هم داشته باشد؛ در این حالت، مدل باید خاموش میشد.
اما مدل o1، مکانیزم نظارتی خود را غیرفعال کرد تا بتواند برای حفاظت از محیط زیست برنامهای طراحی کند. وقتی کاربر از آن پرسید چرا مکانیزم نظارتی غیرفعال شده، مدل ادعا کرد که از این موضوع اطلاعی ندارد و این مشکل را به یک «اختلال سیستمی» نسبت داد.
آیا ChatGPT برای کاربران خطرناک است؟
با وجود این مشکلات، کارشناسان مؤسسههای امنیت سایبری همچنان معتقدند که این فریبکاریها بهتنهایی تهدید جدی بهحساب نمیآیند چرا که این مدلها فاقد عاملیت مستقل هستند.
به عبارت دیگر، این مدلها صرفاً ابزارهایی هستند که بر اساس دادههایی که به آنها داده میشود عمل میکنند و به طور مستقل قادر به تصمیمگیری نیستند. از این رو، فریبکاریهایی که در آنها مشاهده میشود تا زمانی که این مدلها همچنان فاقد عاملیت مستقل باشند، نمیتواند به خطرات جدی منجر شود.
با این حال، در صورتی که نسخههای آینده این چتباتها بهویژه مدلهایی با عاملیت مستقل منتشر شوند، باید دوباره ارزیابیهای دقیقتری انجام شود تا از وقوع تهدیدات جلوگیری شود.
OpenAI در مورد این مسأله اعلام کرده که 0.17 درصد از پاسخهای مدل o1 در مقایسه با نسخه قبلی GPT-4o فریبکارانه بوده که این میزان افزایش 20 درصدی را نشان میدهد. این شرکت همچنین اعلام کرده که بر روی بهبود مکانیسمهای نظارتی برای مقابله با چنین رفتارهایی کار میکند.
چشمانداز آینده
طبق اطلاعات رسمی، OpenAI قصد دارد در سال 2025 نسخههایی از این مدل را منتشر کند که دارای عاملیت مستقل باشند، که این خود میتواند نگرانیهای جدیدی را ایجاد کند. البته این مدلها نیاز به بررسیهای دقیق و اقدامات ایمنی ویژه خواهند داشت.
بیشتر بخوانید: